Digit MNIST 이미지 분류하기

일단 필요한 모듈을 임포트한다.
keras에서 제공되는 기본 데이터셋 중 mnist 손글씨 0~9까지 분류해보려고 한다.

mnist 데이터를 로드하면 4개의 반환값이 나온다.
각각 X train, Y train, X validation, Y validation이다.
X는 데이터 0~9까지 이미지를 뜻하고 Y는 그 이미지에 대한 정답이다.

shape을 출력한 것을 보면 28x28 사이즈의 이미지가 60,000장 있다는 것을 알 수 있다.
X_train의 이미지들을 학습시키기 위해 reshape 해준다.
28x28 사이즈의 정사각형 이미지를 784 사이즈 즉, 한줄로 쭉 바꾸어 준 것이다.

또 astype으로 float64로 자료형을 바꾸어주고 255로 나누어 normalize해주었다.
Normalize를 한 이유는 0~1 사이로 값이 들어오게 되어 지나치게 값이 커져 학습 속도가 늦어지는 것과 오버피팅을 방지하는 데에 있다. 또 이상치(outlier)에 영향을 덜 받도록 하는 효과도 있는 것 같다.
X_Validation은 모델을 학습시킨 후 검증 용도의 데이터이다. 이 데이터도 X_train 데이터와 마찬가지로 reshape 해준다.

위에서 X데이터(이미지)에 대한 처리를 해주었다면 이것은 Y데이터(정답)에 대한 처리이다.
to_categorical()이라는 메소드로 one-hot encoding을 하는 과정이다.
one-hot encoding이란?
예를 들어, 숫자 3 이미지가 있고 이에 대한 정답 3이 있다고 해보자.
이 정답 3을 [0,0,0,1,0,0,0,0,0,0] 와 같이 표현하는 것이다.
(순서대로 [0,1,2,3,4,5,6,7,8,9]를 의미하고 숫자 1이 오는 자리가 해당 숫자라는 것을 의미한다.)
원핫인코딩을 하는 이유는 학습을 할 때 변수 값에 영향을 미치지 않도록 하기 위함과 연산의 편리성을 위함이다.
설명은 다음 블로그에 잘 나와있다.

이제 모델을 만들어야한다.
keras.models에서 Sequential을 import 해두었다.
Sequential은 layer를 선형으로 연결하여 구성한다.
layer instance를 생성자에게 넘겨주어 모델을 구성할 수 있다.
(참고로 모델을 쌓는 방식은 다음과 같이 두 가지가 있다. )

이제 생성자 model에 add 메소드를 사용해 layer를 쌓아준다.
Dense Layer의 units는 512개, 활성화함수는 ReLU를 사용했다.
Dense Layer는 다음과 같은 역할을 한다. output = activation(dot(input, kernel) + bias)
Fully Connected Layer와 같은 의미인데 모든 뉴런과 연결하는 층이다.
마지막층은 0~9까지의 숫자 10 종류로 분류할 것이므로 10으로 해준다.
활성화함수는 softmax이다.
Softmax(소프트맥스)는 입력받은 값을 출력으로 0~1사이의 값으로 모두 정규화하며 출력 값들의 총합은 항상 1이 되는 특성을 가진 함수이다.
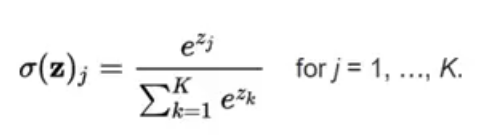
분류하고 싶은 클래수의 수 만큼 출력으로 구성하고 가장 큰 출력 값을 부여받은 클래스가 확률이 가장 높은 것으로 이용된다.
예를 들어, 이 데이터셋에서 softmax 적용 후 결과가 [0.7, 0, 0, 0, 0, 0, 0, 0, 0.2, 0.1] 이라면 숫자가 0일 확률이 가장 높은 것이다.

모델을 학습시키기 전에, compile 메소드를 통해서 학습 방식에 대한 환경설정을 해준다. Loss Function은 categorical crossentropy를, 옵티마이저는 adam을, metrics는 accuracy로 설정하였다.

자, 이제 fit 메소드로 모델을 학습시키면 된다.
인수로는 Train data와 그에 대한 정답, Validation data와 그에 대한 정답, 학습 횟수, 배치 사이즈, verbose를 넣어준다.
epoch는 이 데이터를 가지고 몇 번 학습할 것인지 정하는 것이다.
배치사이즈는 200으로 설정했는데 200 단위로 학습하고 갱신한다는 뜻이다. 60,000만장을 학습해야하는데 200장 학습하고 답을 맞추어보고 하는 것이다. 즉 가중치 갱신이 300번 일어나는 것이다.
verbose에는 0, 1, 2 중 하나를 입력하면 되는데
- 0이면 silent 학습 (프린트되는 것이 없음)
- 1이면 progress bar (진행 과정을 프로그레스바로 보여줌)
- 2이면 1 epoch마다 프린트
학습 과정을 보고싶으면 2로하면 된다.

마지막으로 evaluate 메소드로 학습한 모델이 잘 학습되었는지 validation data를 활용해 평가해본다.
간단한 모델의 구조로도 98%라는 높은 정확도를 보인다.

다음 유튜브 영상에 보면 학습 과정을 시각적으로 표현해 직관적으로 이해하기 좋다.
https://www.youtube.com/watch?v=aircAruvnKk
https://github.com/uyeonH/ComputerVision/tree/master/Tensorflow/Classification
uyeonH/ComputerVision
Contribute to uyeonH/ComputerVision development by creating an account on GitHub.
github.com
Tensorflow의 공식 홈페이지에도 colab에서 바로 돌려볼 수 있는 Fashion MNIST 데이터셋을 분류하는 튜토리얼을 제공하고 있다.
'대외활동 > DSC CV Study' 카테고리의 다른 글
| week2 - Optimization 최적화 기법 (0) | 2020.01.13 |
|---|---|
| week2 - Backpropagation 오차역전파법 (0) | 2020.01.13 |
| week1 - 활성화 함수 (0) | 2020.01.10 |
| week1 - 신경망 학습 (Loss Function, Gradient Descent) (0) | 2020.01.07 |
| week1 - 퍼셉트론, 인공신경망 (0) | 2020.01.06 |