Machine Learing의 분류
- Supervise Learning(지도학습)
- Unsupervised Learning(비지도학습)
- Reinforcement Learning(강화학습)
강화학습 ?
강화라는 개념은 행동심리학자 시크너가 제시한 것으로 행동심리학에서 영감을 받았다고한다. 강화는 동물이 시행착오를 통해 학습하는 것을 말한다. 강화학습은 이 동물처럼 어떤 환경에서 Agent가 경험을 통해 Reward가 최대가 되도록 하는 Action을 상황별로 결정하는 것을 말한다. 지도학습처럼 Label(정답)을 주어 계속해서 옳은 방향으로 나아가는 학습 개념과는 조금 다르다. 사람처럼 실수도 하고 시행착오도 겪는 그런 모습을 표현(적용)한 것이라고 한다.
강화학습의 정의
"어떤 환경 안에서 정의된 Agent가 현재의 State를 인하여,
선택 가능한 행동들 중 보상을 최대화하는 Action 혹은 그 순서를 선택하는 방법"
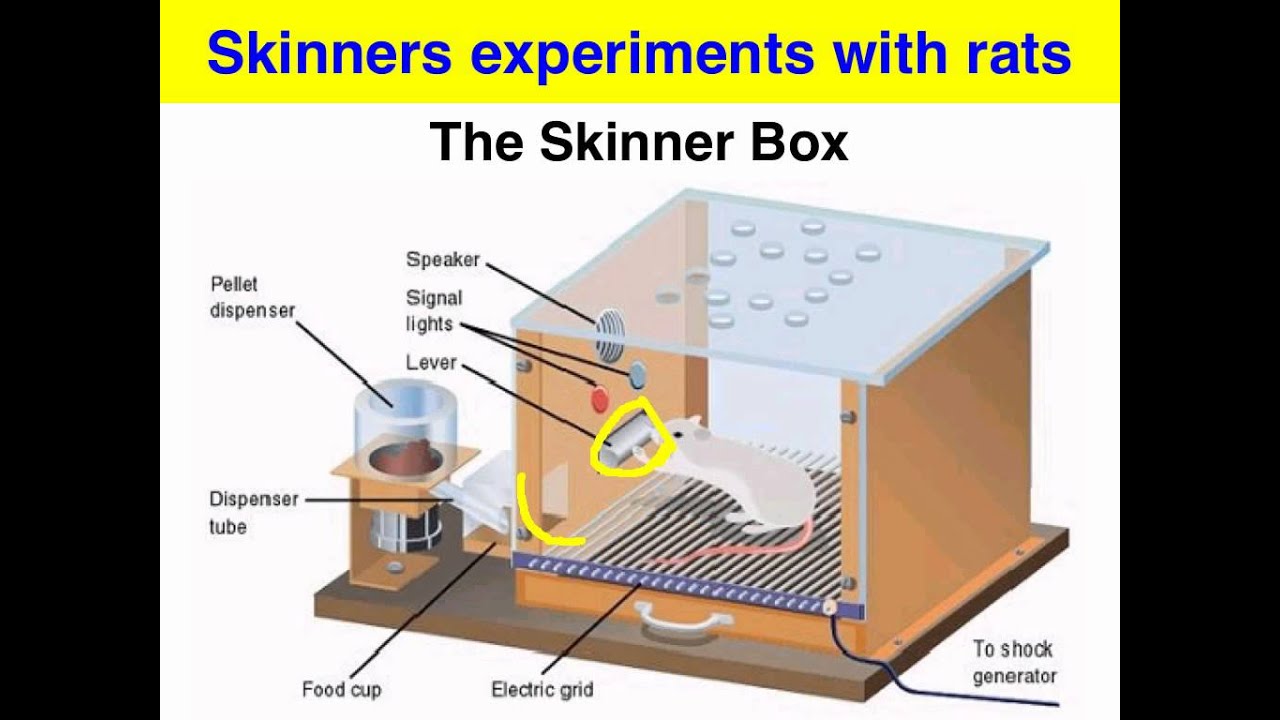
Skinner Box 스키너 상자
보상/처벌 메커니즘을 통한 조건 형성과 교육에 관한 동물 실험
Skinner box는 동물 행동을 연구하는데 사용되는 실험 기구이다. 실험용 동물에게 빛이나 소리 신호와같은 특정한 자극에 대한 반응으로 특정한 동작을 학습시켜 조건 형성을 연구할 수 있는 도구이다. 실험용 동물이 정확한 행동을 취하면 스키너 상자의 장치가 음식이나 다른 보상을 준다.
어떤 Action을 했을 때, 행동에 대한 Q(Quality)를 알려주는 것을 Q Learning이라고 한다.
이것에 Deep Learning을 적용한 것을 Deep Q Learning이라고 한다.
해서 인간 Level을 뛰어넘게 되었다(?)
DQN
Agent가 환경으로부터 샘플을 선택하면 샘플간의 상관관계가 높기 때문에 학습에 좋지 않은 영향을 미친다. 그래서 이 샘플들을 Replay Memory에 저장하고 random하게 셀렉하여 학습에 이용하는데 이것을 Experience replay라고 한다.
순차적 결정문제 MDP
강화학습 문제는 MDP(Markov Decision Process)로 표현된다.
상태(State)와 행동(Action)이 있고 이에 따른 인과(Causality) 가 있다.
Agent는 이 행동의 주체가 된다.
벨만 방정식
Q^∗ (s_t,a_t^ )=R_(t+1)+max┬a〖Q^∗ (s_(t+1),a)〗
Greedy보단 Global 하도록 !!
여기서 Greedy는 지금 당장 이득이 될만한 쪽을 선택하는 것, Global은 먼 미래의 가치까지 생각하는 것이다.
R은 즉각적 보상을, Q는 a 먼 미래의 가치를 뜻한다.
신경망이 Policy 역할, parameter theta
다음 Agent로 상태 전이
Policy가 Agent의 뇌라고 생각할 수 있고 Quality가
기억의 Instance를 저장 / 현재상태 + 다음상태 + 행동 + 보상
이 배치를 가지고 학습시킨다.
breakthrough
\- Correlations between samples: experience buffer의 인접한 값들은 유사하다. 그대로 가져와서 학습시키면...... 랜덤으로 뽑은 샘플로 학습을 시킨다.
\- Non-stationary targets:
Epsilon-Greedy
Exploration = 탐험, Exploitation = 이용
Exploration과 Exploitation을 높이기 위한 정책: Epsilon
더 높은 보상을 받기 위해서는 주어진 상황에서의 더 적절한 행동을 Exploit 해야한다.
이때 각 Action들의 가치에 대해 알기 위해서는 사전에 탐험(explore)을 할 필요가 있다.
Exploration을 위해 지금 당장 최선이라고 믿어지는 action을 포기할 수도 있어야한다.
Exploration-exploitation dilema
항상 알고있는 확실한 길로만 다닌다면? Local Minima
가끔씩 탐험 정신으로 다른 길로도 가본다면? Approaches to global minimum
Q Learning의 원리를 이해하기 위해 미래 가치가 현재의 행동에 어떻게 전달되는지가 중요하다.
샘플들간의 연관성을 제거해야한다.
목표값을 얻어내는 네트워크와 정책 네트워크를 분리해야한다.
e-greedy 정책을 통한 모델의 일반화
적용 분야의 Domain을 이해하고 "Enviroment"에 맞게 코딩할줄 알아야한다.
해당 논문을 읽어보기를 추천한다고 하셨다↓↓↓
Reference